📢 Accepted at IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2025
Predicting human behavior in shared environments is crucial for safe and efficient human-robot interaction. Traditional data-driven methods to that end are pre-trained on domain-specific datasets, activity types, and prediction horizons. In contrast, the recent breakthroughs in Large Language Models (LLMs) promise open-ended cross-domain generalization to describe various human activities and make predictions in any context. In particular, Multimodal LLMs (MLLMs) are able to integrate information from various sources, achieving more contextual awareness and improved scene understanding. The difficulty in applying general-purpose MLLMs directly for prediction stems from their limited capacity for processing large input sequences, sensitivity to prompt design, and expensive fine-tuning. In this paper, we present a systematic analysis of applying pre-trained MLLMs for context-aware human behavior prediction. To this end, we introduce a modular multimodal human activity prediction framework that allows us to benchmark various MLLMs, input variations, In-Context Learning (ICL), and autoregressive techniques. Our evaluation indicates that the best-performing framework configuration is able to reach 92.8% semantic similarity and 66.1% exact label accuracy in predicting human behaviors in the target frame.
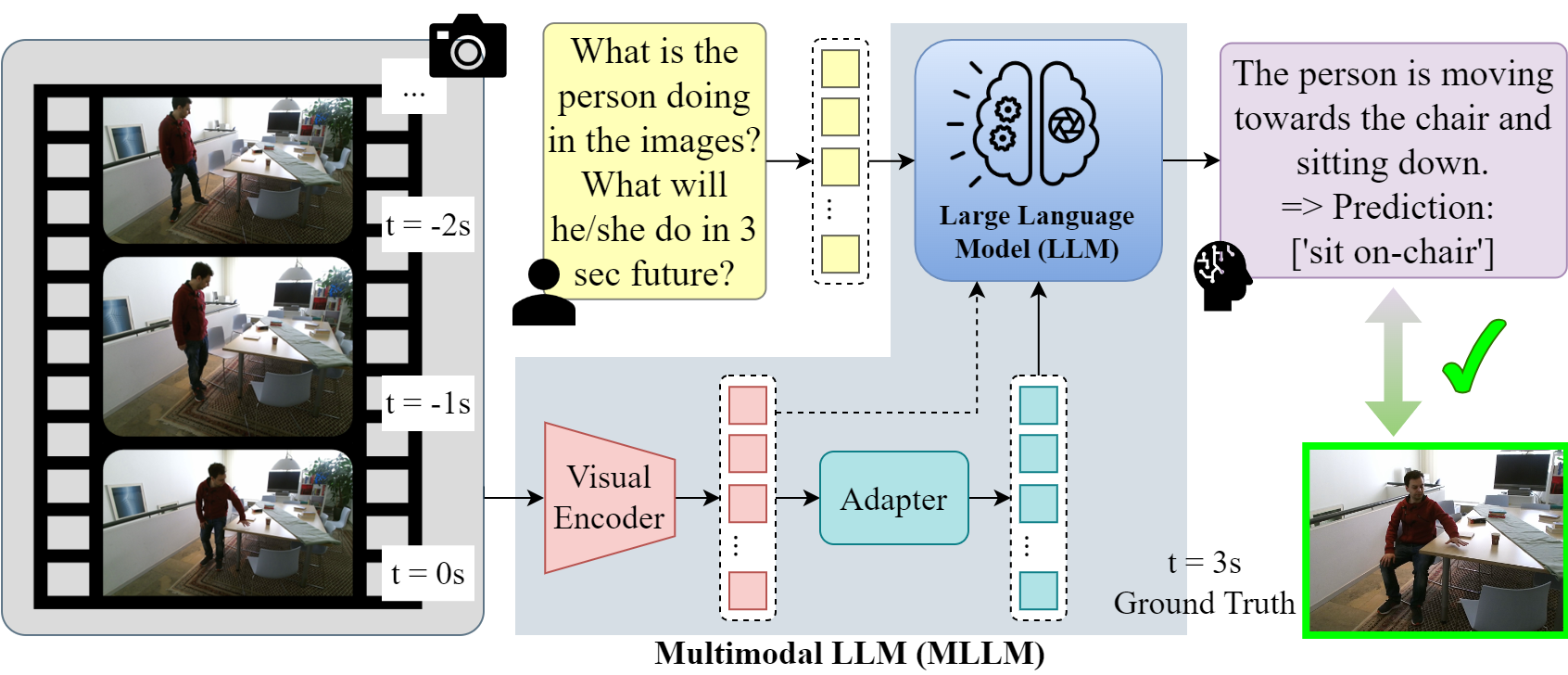
System overview for human behavior prediction with scene context. The top part depicts the ground truth human interactions. The prediction system is illustrated in the lower part, which consists of an MLLM that is instructed with a prompt including the task description to predict future interaction labels and a set of In-Context Learning (ICL) examples. We ablate the visual input with four types of visual context representations: blind (no visual input), image, image sequence, and image caption, varying from one to three past time steps. An autoregressive prediction step is added to improve the predictions, which predicts the intermediate action labels.
We formulate and evaluate several hypotheses on building a performant prediction system:
H1: MLLMs are capable of correctly predicting non-trivial sequences of human activities (i.e., such where the target label is different from the latest observation, or where multiple correct activity labels are given as the ground truth).
H2: Adding visual context yields more accurate predictions, compared to using purely text-based LLMs.
H3: Prediction accuracy generally improves with the number of ICL examples, compared to zero-shot prediction.
H4: Predicting intermediate actions between the current and the target time frame in an autoregressive manner improves the accuracy.
Our evaluation supports the hypotheses H1, H2, and H3. Firstly, many configurations can deliver competitive results without additional fine-tuning for correctly predicting non-trivial sequences of human activities. Furthermore, incorporating additional visual context and more ICL examples yields the best performance.
Examples of human behavior predictions. The last row depicts a false prediction that differs from the ground truth.
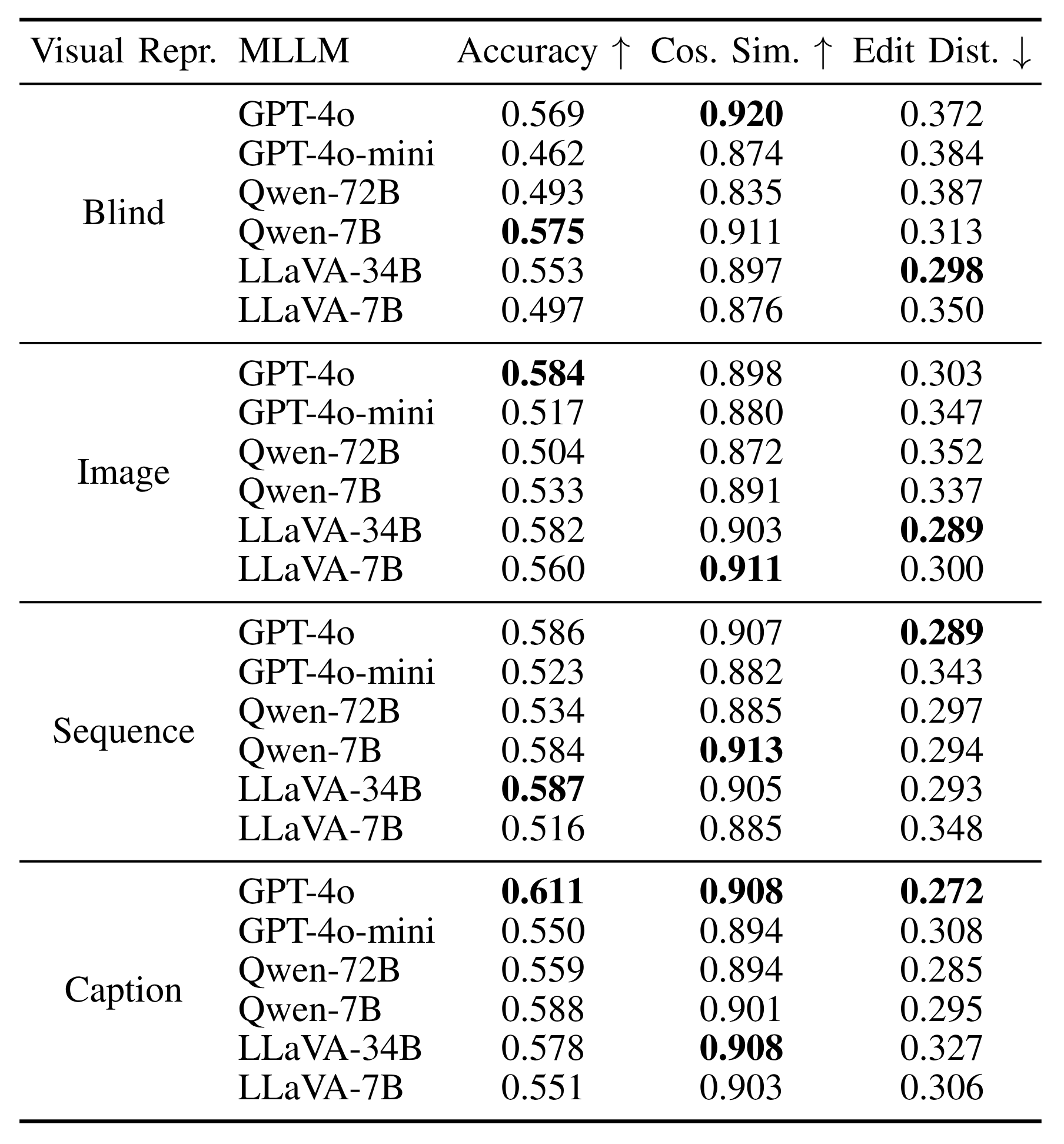
Results of Zero-Shot Prediction. Higher values of accuracy and cosine similarity and lower value of edit distance indicate better performance. Bold numbers indicate the best results in each visual representation.
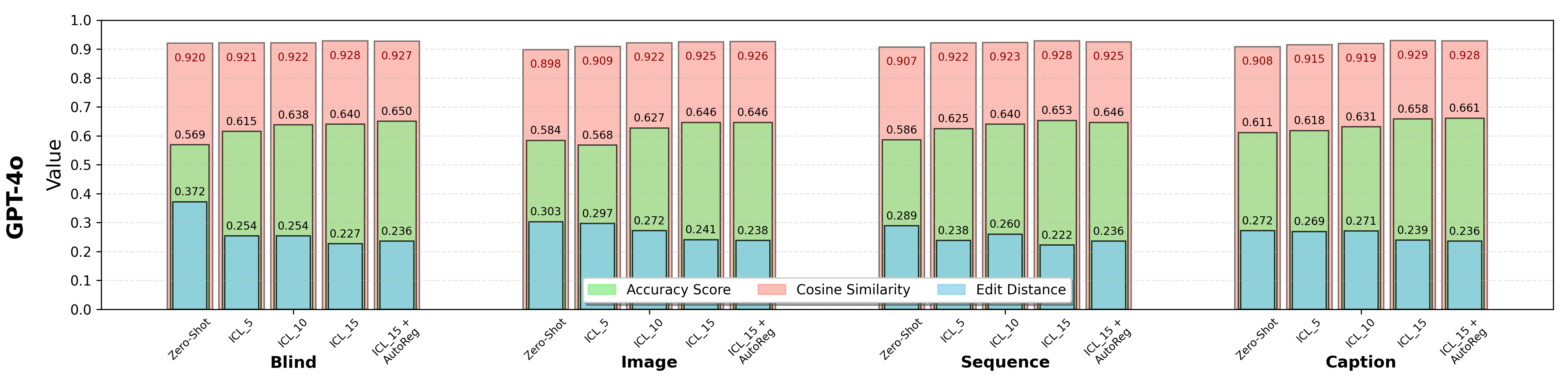
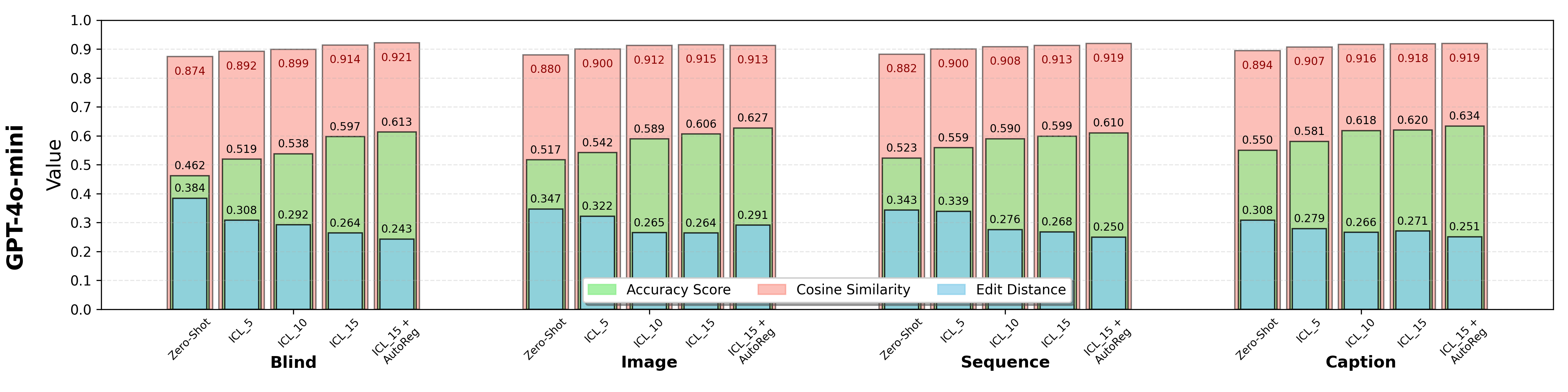
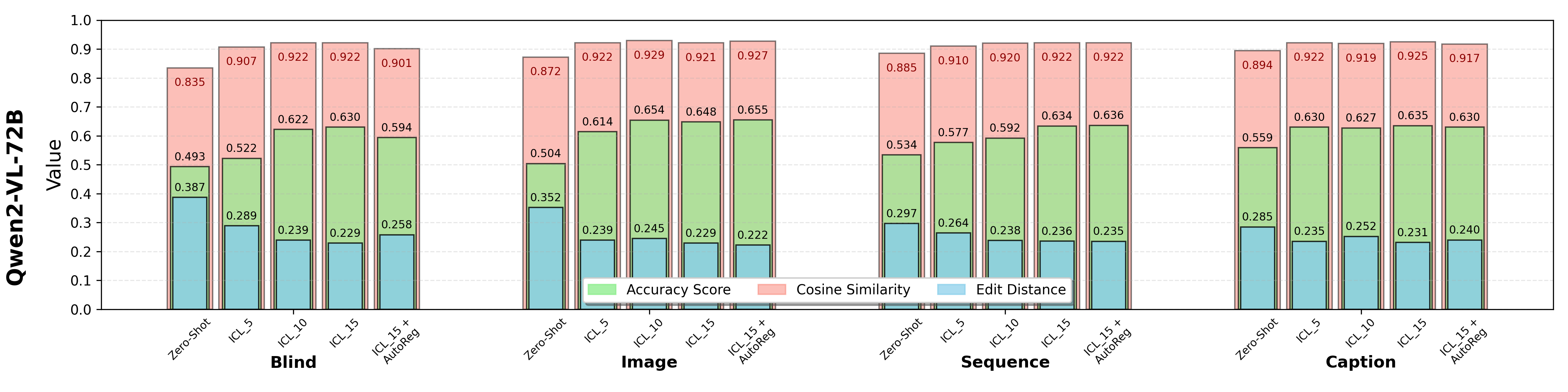
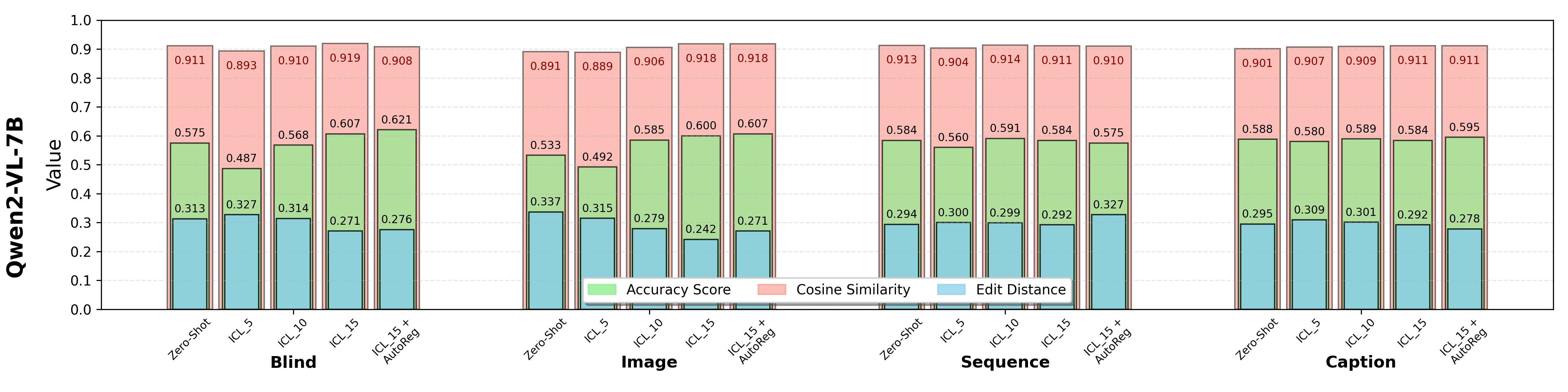
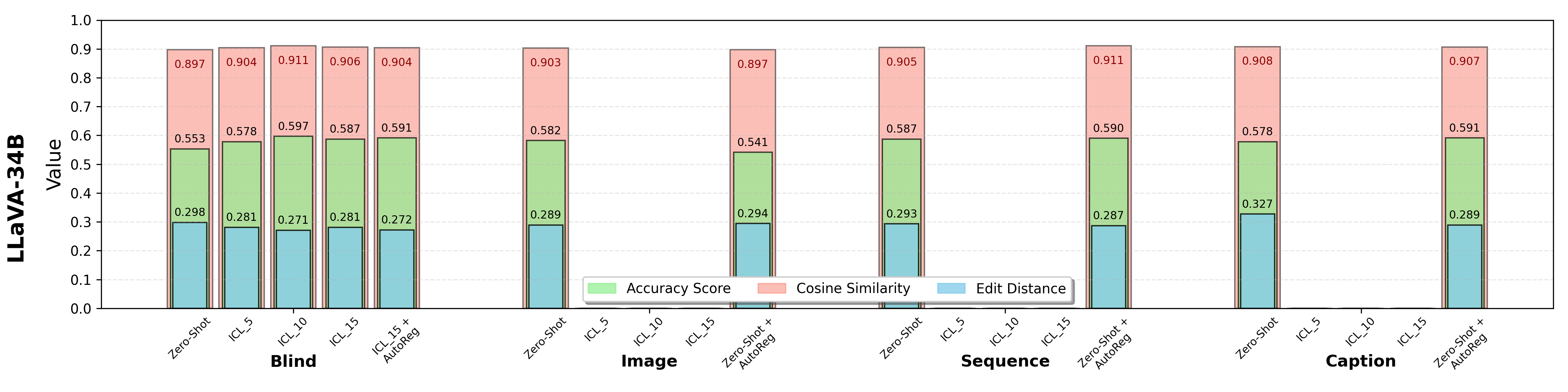
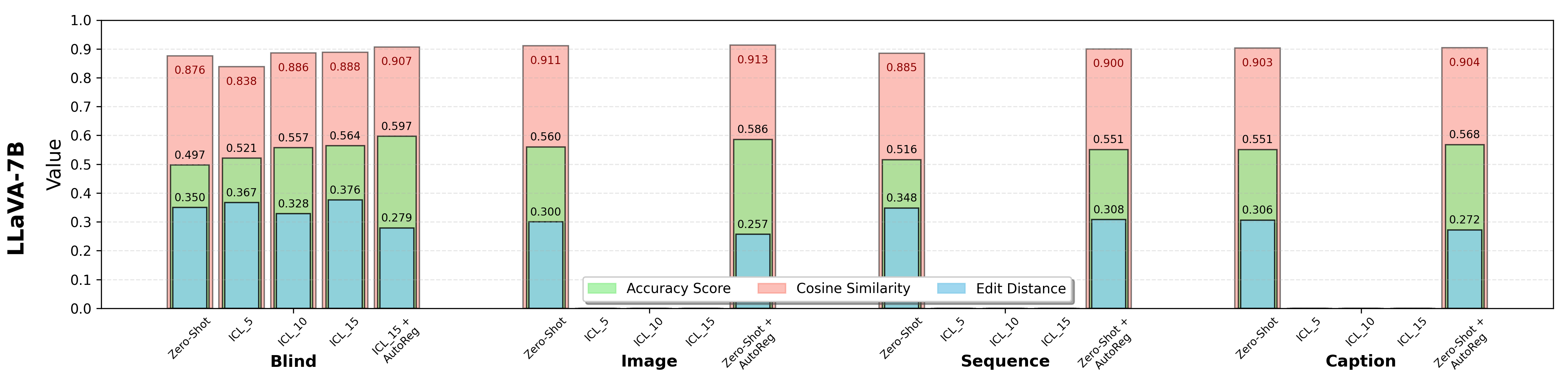
* LLaVA models seem to be unsuitable for ICL. This is potentially caused by its prompt template that always first renders all images before processing the text. The missing tokenize-in-place ability leads to the mismatching of example and query images, therefore consistently resulting in failures and generating corrupted output tokens. (Source: https://huggingface.co/llava-hf/LLaVA-NeXT-Video-7B-hf/discussions/3).
@article{liu2025context,
title={Context-aware human behavior prediction using multimodal large language models: Challenges and insights},
author={Liu, Yuchen and Lerch, Lino and Palmieri, Luigi and Rudenko, Andrey and Koch, Sebastian and Ropinski, Timo and Aiello, Marco},
journal={arXiv preprint arXiv:2504.00839},
year={2025}
}